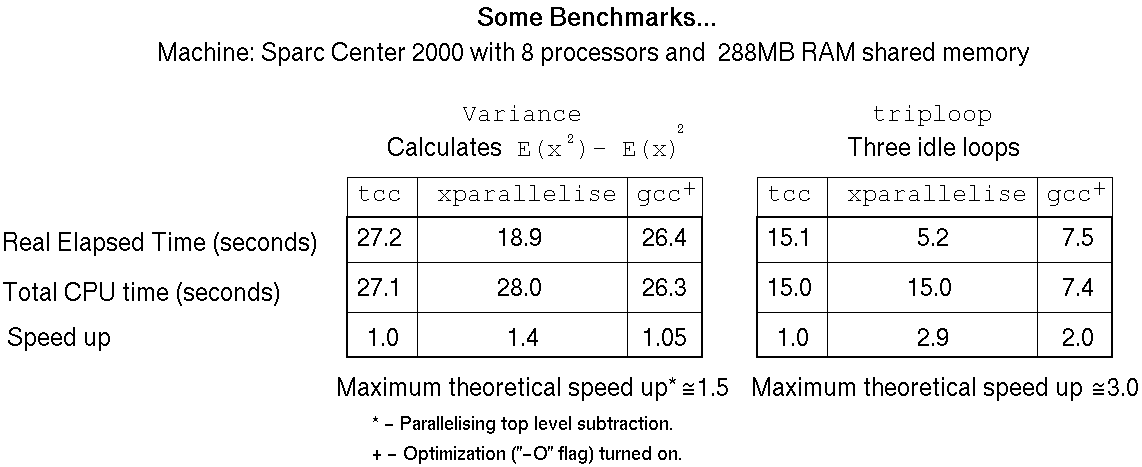
Some Experimental Results
The algorithm described in this paper has been implemented and integrated
into a parallelizing compiler for the
ANDF language (an ANDF-to-ANDF
parallelizing compiler). The results
presented here have been obtained using this implementation.
(To obtain more information on this project please contact the
authors).
This set of results illustrates two optimal cases where a parallelizing
compiler employing this algorithm can achieve very good results.
This kind of optimal case arises when in an acyclic code
region analyzed by the
parallelizer there are two or more blocks of code for which:
- The data dependence analysis algorithms are clever enough to
discover that the blocks of code are not data dependent between them.
- The partitioning algorithm is clever enough to determine that the
the blocks of code have enough granularity to justify generating threads
for parallel execution.
The two examples presented here are:
- A small program performing a subtraction, where the calculation of
each element is performed independently of the other
and takes a significant amount of time.
- A small program executing three independent idle
loops.
The data presented compares runs from three different compilers.
- tcc
- A front-end driver for a set of ANDF tools
performing the C-to-ANDF-to-machine translation steps.
- xparallelise
- The parallelizing compiler (driven by a graphical
interface). tcc is used by the parallelizer to generate the
ANDF capsule file from the C
source, and also to generate the final executable from the parallelized
ANDF capsule.
- gcc
- Do I need to say anything ? (version 2.6.1)
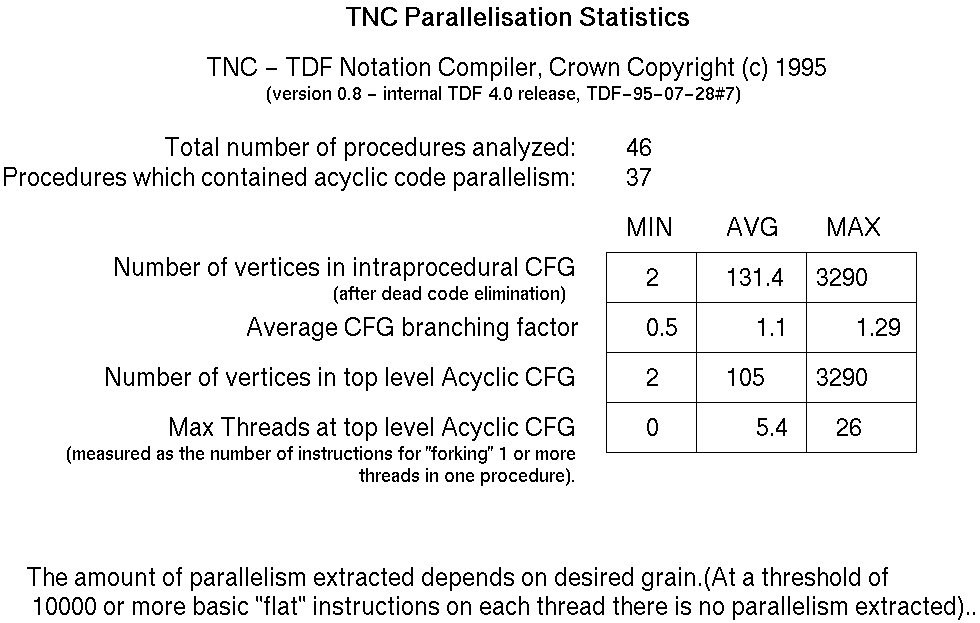
 TNC is an ANDF tool that converts ANDF
binary capsules into a readable text format and vice-versa
(a notation compiler).
TNC is an ANDF tool that converts ANDF
binary capsules into a readable text format and vice-versa
(a notation compiler).
The following data was gathered using the ANDF
parallelizing compiler to parallelize the top-level acyclic code
region of each procedure.
Some Considerations
These runs cannot be taken as a reference results for evaluating the
algorithm. Much more runs would have to be performed on a larger set of
programs, and more elaborate data dependences analysis and
preliminary code transformations can still be implemented.
Nevertheless, we feel that the run on
"Parallelizing a Compiler" somewhat reflects
our experience with non number-crunching applications written in C,
which typically manipulate heap based data structures (lists and so on)
and perform IO operations.
The bad news in our experience is that, although some fine-grain
parallelism (almost at instruction level) can be found on most functions,
it cannot be exploited in conventional multi-threaded code
with the (relatively) large overheads of thread management operations.
The algorithm results are dependent on the quality of the
data dependence analysis and grain estimation components. It is still
unclear where a much more elaborate data dependence analysis
can significantly improve the results.
The good news is that, even with a simple heuristic
method for determining the minimum acceptable grain for parallelism, the
parallelizer was able to successfully exploit the cases where this
algorithm achieves good speedup results (as in
"Parallelizing Independent Loops")
and to avoid the generation of parallel code for the cases
where the inefficient exploitation of fine-grained parallelism
would result in loss of speed (as in
"Parallelizing a Compiler").
Back to the main page.