Preview
This is a short illustration on how the algorithm operates
in extracting parallelism
from acyclic code regions through a
a simple example (without complicated issues).
If this is the kind of algorithm you are
looking for, then it might be worth retrieving and
printing the whole article.
Input Data
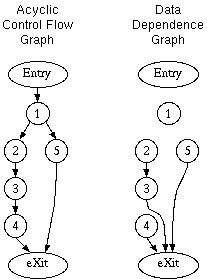
The algorithm extracts parallelism from an acyclic code region represented
by an acyclic Control Flow Graph
(with a single Entry and a single eXit vertex) and a
Data Dependence Graph.
Upper Bound for Parallelism
The algorithm then builds the Control Dependence Graph
and uses it to build a Petri Net that models parallel
execution of that code region constrained by control dependences.
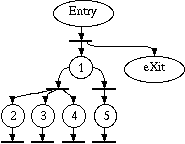
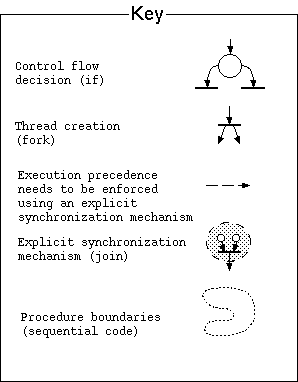
(If you are unfamiliar with the symbols
used in this net, check the key table).
Sequencing code
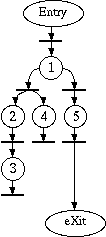
The algorithm then looks at each data dependence, and attempts to
sequence code if to prevent parallel executions where memory locations
are accessed out of order.
In this example, places 2 and 3 in the net are sequenced
in order to enforce an execution order that respects
the data dependence between vertices 2 and 3.
The eXit place is also sequenced with place 5 with this
algorithm, because of the date dependence between vertex 5 and
eXit. Data dependences from vertices 3 and 4 cannot be handled
by sequencing code
once the transformation involving place 5 and eXit is performed.
Essential Dependences
Milind Girkar's algorithm
(see
"Functional Parallelism: Theoretical foundations and Implementation")
is then applied
to find which data dependences still
need explicit synchronization to
enforce a correct execution precedence.
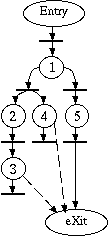
In this example, ensuring that vertices 3 and 4 finish execution before
vertex eXit starts,
has to be enforced using explicit synchronization.
Explicit Synchronization
Explicit synchronization
mechanisms are inserted to enforce
execution precedence.
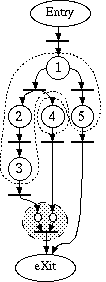
The doted lines around some net regions represent possible code
regions that could be gathered into a single procedure, if we were to
generate conventional multi-threaded code where each thread must have a
procedure as an entry point.
The dashed filled circle represents an explicit synchronization
mechanism created to enforce execution precedence for the eXit
vertex.
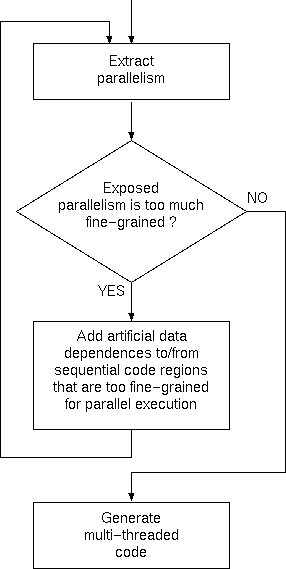
Partitioning
One of the advantages of this algorithm is that it can be used within
an iterative partitioning framework (such as the one described by the
following algorithm) to
generate solutions with increasingly larger grain of parallelism, up
to a desired level.
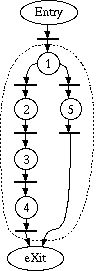
In this example, if we consider that place 4 represents a task
that is to small to justify the overheads of creating a thread just for
executing it, we can add artificial dependences around vertex 4
and re-execute the parallelism extraction algorithm to produce a
solution with less parallelism.
In this case, we add data dependences from vertex 2 and vertex 3 (the
vertices in its neighbor concurrent region) onto vertex 4 (2->4 and
3->4 added to the Data Dependence Graph).
The resulting solution (in this particular case) has no parallelism, and
efficient sequential code can be generated for it.
Back to the main page.