


Next: Client Session Management
Up: The I*Tea Application Server:
Previous: Introduction
In this paper we will describe the I*Tea version which interfaces
with browsers through CGI technology.2
An operating I*Tea application site usually involves the following
software:
-
Web Client -
A Client is usually a user's browser which performs HTTP GET
or POST requests.
-
Web Server -
A server process which receives HTTP requests and takes appropriate
action.
-
cgi2itea-
A small executable CGI program wich interfaces the I*Tea Server
process with the Web Server .
-
I*Tea Server -
A standalone process, which receives requests from the cgi2itea,
executes them, and passes the response back to cgi2itea.
I*Tea is entirely written in Java , inheriting all the advantages
of such a technological choice. Its runtime environment occupies
a surprisingly low disk space (approx. 1MB, including the Tea
runtime environment).
The I*Tea Server is a multi-threaded Java process which can be modelled
as a set of software components (data and threads)
which communicate between them:
-
Client Data -
A simple data storage hastable, private to each Web Client . It can only be
accessed through a set/get key value hashtable like API.
The values store in this hashtable can be simple Tea data objects
(integers, strings, etc...)
More complex data structures have to be serialized/de-serialized
if to be stored in such a way. For those situations
we suggest using a separate Tea Interpreter Context for each Web Client .
-
Tea Interpreter Context -
Object binding context for executing Tea code
(ie. the bindings between variables/values for Tea scripts executed
under the I*Tea Server ).
Recall that the Tea language supports integers, floats, strings,
symbols, lists, vectors, hashtables, global variable bindings,
nested code blocks (code with local variable bindings), functions as first
class objects (lambdas), programming modules (files defining
public and private functions and variable bindings), and object oriented
programming (class based with single inheritance). It has a simple syntax
and powerful semantics that allow a programmer to extend the language
based on the language itself.
As such, a program written in the Tea language can have very
complicated object structures.
(See documentation on the Tea language for more information).
-
Main Server Thread -
The Main Server Thread accepts connections from the cgi2itea
and places them in the request queue. (The number of pending requests is
configurable by the programmer.)
-
Thread Pool -
The Thread Pool contains a configurable number
of idle threads
waiting for requests to be placed in the Request Queue.
When an idle thread acquires a pending request, it:
- 1.
- Identifies the Web Client by the HTTP cookie provided. If the Web Client has
no cookie, then it is a new Web Client and a new Client Context
is created. A configurable operating mode parameter specifies if
the Client Context is given a new Tea Interpreter Context,
or to reuse one. (Configurable parameters limit the number of
Client Contexts allowed and their idle lifetime.)
- 2.
- Parses a document specified by the URL and configuration
parameters. This document can
be a single Tea script (wich is executed), or a textual document
(HTML for example) with embedded Tea script blocks.
Each Tea script block runs under the appropriate
Tea Interpreter Context
and has access to the Client Data
(private for this Web Client ) through the I*Tea API.
- 3.
- Flushes the data outputed during document parsing back to the
calling cgi2itea.
The I*Tea Server is dynamically linked with the Tea interpreter
code (also written entirely in Java ) and with other Java
class libraries which give it access to whatever the
application programmer might need (JDBC for relational database
access, TCP/IP APIs, etc...)
A typical interaction with a Web Client goes like described in
figure 1.
Figure 1:
HTTP request interaction
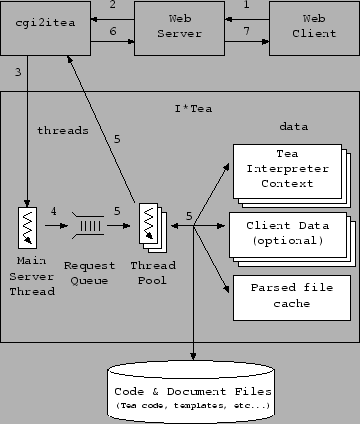 |
- 1.
- The Web Client issues an HTTP request to the Web Server (by following
a link or submitting a form).
- 2.
- The Web Server receives the HTTP request, and, if the URL requested
corresponds to a cgi2iteainvocation, spawns the process and passes
it the information of the request (as defined by the CGI specification).
- 3.
- The cgi2iteaspawned by the web server reads the HTTP request
information supplied by the Web Server , opens a TCP/IP connection
to the I*Tea Server and passes it this information.
- 4.
- The Main Server Thread from the I*Tea Server accepts the connection from
cgi2itea, reads the request parameters and places them in a request
queue.
- 5.
- An idle thread picks up the request, selects the appropriate
Client Data and Tea Interpreter Context for this Web Client , and
parses the document specified by the URL, executing the whole document
as Tea script, or expanding text embeded Tea script blocks.
The Tea script blocks can access the request parameters,
access the Web Client's private Client Data and manipulate
its own variables in its Tea Interpreter Context and dynamically import and
use Tea or Java libraries.
Requests are serialized for each Web Client , so there is usually
no need to worry about concurrency when manipulating these resources.
At any time, the script can output data through I*Tea API function
calls and libraries to be sent back to the Web Client .
- 6.
- The cgi2iteareads the output from the I*Tea Server , and
passes it back to the Web Server , closes its connections and
dies.
- 7.
- The Web Server passes the cgi2iteaoutput back to the browser
(which should render it on the user's browser window),
closes its HTTP connection, and it is ready for another request.
Next: Client Session Management
Up: The I*Tea Application Server:
Previous: Introduction
Systems Consultant
2000-09-25